

DevOps, Continuous Delivery & Database Lifecycle Management
Version Control
To achieve reliable, repeatable database builds and migrations, as part of Database Lifecycle Management (DLM), we need to store the Data Definition Language (DDL) code for a database in a version control system (VCS). It should be possible to reconstruct any version of a database from the scripts in the VCS and every database build we perform, and every database change, however trivial, should start from version control.
Ideally, you will also have in the VCS a complete history of changes to individual schemas and objects; who did them and why. Any build and version-control system must allow developers, as well as people outside the development team, to be able to see what is changing and why, without having to rely on time-wasting meetings and formal processes.
Without good version control practices, large parts of DLM will remain difficult for your organization to achieve, so getting it right is vital. In this article, we explore the database versioning capabilities provided by source control system, considerations when choosing a one, and good practices for version control in the context of DLM.
What goes in version control?
Every application or database that we build should originate from a version in the source control system. With most developments, there are many points in the process where a consistent working build should be available. You need to store in version control everything that is needed in order to build, test or deploy a new database, at a given version, or promote an existing database from one version to another.
The most obvious candidates for versioning are:
- individual DDL scripts for each table
- individual DDL scripts for all other schema-scoped objects such as stored procedures, functions, views, aggregates, synonyms, queues
- ‘static’ data
There are other candidates that we will mention shortly. If a VCS saves database scripts at the ‘object’ level then each file corresponds to a table or routine. In this case, the task of creating a new database or upgrading an existing one, from what’s in source control, is primarily an exercise in creating an effective database script from the component ‘object’ scripts. These will have to be executed in the correct dependency order. Subsequently, any static data must be loaded in such a way as to avoid referential constraints being triggered.
An alternative is a migration-based approach, which uses a series of individual change scripts to migrate a database progressively from one version to the next. The Database Migrations article discusses these approaches in more detail.
However they are produced, we need to also version the complete build script for the database structure and routines, as well as the data migration scripts required to ensure preservation of existing data during table refactoring, plus associated rollback scripts. Normally, the complete build scripts would be generated automatically from the nightly integration build, after it has passed its integration tests (see the Database Continuous Integration article). These integration tests will also verify that any hand-crafted migration scripts work exactly as intended, and preserve data correctly.
A common mistake that development teams make is to assume that database source code consists merely of a number of ‘objects’. In fact, the dependencies within a working database system are numerous and sometimes complex. For example, a change to one item in the database configuration, such as the database collation setting, might be enough to stop the database working as expected. Therefore, beyond the tables, routines and static/reference data, we also need consider the broader database environment, and place into version control elements such as:
- database configuration properties
- server configuration properties
- network configuration scripts
- DDL scripts to define database users and roles, and their permissions
- database creation script
- database interface definition (stored with the application it serves)
- requirements document
- technical documentation
- ETL scripts, SSIS packages, batch files and so on
- SQL agent jobs.
Benefits of version control
Unless we have in the VCS the correct versions of all the scripts necessary to create our database objects, load lookup data, add security accounts, and take any other necessary actions, we have no hope of achieving reliable and repeatable database build, release and deployment processes, nor of coordinating database upgrades with changes to the associated application. If we perform ad – hoc database patching, outside of a controlled VCS process, it will inevitably cause data inconsistencies and even data loss.
Version control provides traceability
The VCS provides a complete history of changes made to the database source. The team can see which developer is working on which particular module, which changes have been applied and when they were applied, which modules are available for release, the current state of the production system and the current state of any test systems. It also means that the team can, at any time:
- Roll the database forward or back between any versions
- Recreate older database versions to find when a subtle bug was introduced.
- Perform a code review, checking coding standards and conventions
This traceability is crucial when diagnosing incidents in Production or when responding to an internal or external audit, and is particularly powerful when using hash-based VCS tools such as Git, which trace the file contents. With the correct permissions scheme in place, a VCS provides a trail of changes to all text files used in the software system.
Version control provides predictability and repeatability
Keeping all text-based assets in version control means that processes are more repeatable and reliable, because they are being driven from a controlled set of traceable files rather than, for example, arbitrary files on a network share. The modern VCS is highly reliable and data loss is extremely rare, making it ideal to depend on for automation.
Version Control protects production systems from uncontrolled change
The VCS acts as a guard against ‘uncontrolled’ database changes i.e. against direct changes to the code, structure, or configuration of a production database. The VCS must be treated as a single source of truth for the database source, and configuration, including database schema, reference data, and server-level configuration settings.
The VCS is a mechanism to ensure that the database source that has been stored is identical to what was released. Before deploying a new database version, the team can compare the target database with the source scripts for that database version, in the VCS. If they do not describe identical databases, then the target database has drifted. In other words, there have been unplanned and untested fixes or functionality updates made directly on the live database, and the team must find out what changed and why.
Version control aids communication between teams
Current version control environments offer rich, browser-based features for collaboration, communication, and sharing between teams, helping to foster interaction and engagement. Features such as pull requests, tickets or issue tracking, and commenting promote good practices such as code review and coding in the open.
A VCS platform that makes it easy for DBAs or Ops teams to review proposed database changes, while automatically storing all the traceability information, will encourage tight feedback loops between Ops and Dev and other stakeholders.
Choosing a version control system for DLM
A good source control system should make it simple for people across the organization to track changes to files. Usability should be high on the wish-list for any VCS, particularly if it must be easily-accessible to other teams besides developers, such as testers and database administrators, as well as governance and operations people.
Version control tools
We need to distinguish between low-level version control tools, usually a combination of client tool and server engine, such as Git or Subversion, and version control platforms that provide deep integration with other tools and a rich, browser-based user experience, such as Github or Bitbucket Server (previously known as Stash). We cover tools in this section, and platforms in the section, Version control platforms.
Git
Git’s superior workflow model together with lightweight branching, merging, and history operations make Git the best choice for most teams. Unless you have a good reason to do otherwise, you should use Git as the version control repository part of your VCS. All modern VCS tools support Git, including Microsoft’s Team Foundation Server.
Mercurial
Mercurial is similar to Git, they both use similar abstractions. Some advocate that Mercurial is more elegant and easier to use while others claim Git is more versatile. So it comes down to a matter of personal choice. Certainly, Git is the more widely-adopted tool due to the rise of platforms like GitHub.
Subversion
Subversion is a sound choice for smaller repositories or where there is a fast network connection to the central server. Subversion can also act as a low-cost artifact repository for storing binary files.
Team Foundation Server
Team Foundation Server (TFS) 2015 and later support Git as the versioning tool. If you use an older version of TFS, you should either switch to an alternative VCS or upgrade to TFS 2015 or later in order to take advantage of Git support. The older versions of TFS have features and quirks that significantly hamper Continuous Delivery and DLM; in particular, older versions of TFS require an instance of SQL Server per TFS repository, which acts as a significant driver to use only a single repository across several teams, or even an entire organization, rather than having many small repositories that are cheap and quick to create.
Centralized vs. distributed?
Some people distinguish between ‘centralized’ and ‘distributed’ version control systems, but these distinctions can become quite academic, because most teams today use a definitive central repository, even when using a distributed VCS.
Distributed version control systems (DVCS) don’t require users to be connected to the central repository. Instead, they can make changes in their local copy of the repository (commit, merge, create new branches, and so on) and synchronize later. Pushing changes from the local repository and pulling other people’s changes from the central repository are manual operations, dictated by the user.
In centralized systems, by contrast, the interaction is between a local working folder and the remote repository, on a central server, which manages the repository, controls versioning, and orchestrates the update and commit processes. There is no versioning on each client; the users can work offline, but there is no history saved for any of these changes and no other user can access those changes until the user connects to the central server, and commits them to the repository.
The different approaches have important implications in terms of speed of operations. In general, command execution in DVCS is considerably faster. The local repository contains all the history, up to the last synchronization point, thus searching for changes or listing an artifact’s history takes little time. In a centralized system, any user with access to the central server, can see the full repository history, including the last changes made by teammates or other people with access to the repository. However, it requires at least one round-trip network connection for each command.
In my experience, more teams are now opting for the support for the speed and support for asynchronous work that DVCS offers, but it’s worth remembering that with them often comes a more complex workflow model, due to their asynchronous nature. I believe that either flavor of VCS, centralized or distributed, can work well as long as it fits with the preferred workflow of the team, and provided that the right culture and accountability exists in the team.
With either system, if the team allow changes to live for too long in individual machines, it runs counter to the idea of continuous integration and will cause problems. In a DVCS, users feel safer knowing their changes are versioned locally, but won’t affect others until they push them to the central repository. However, we still need to encourage good CI practices such as frequent, small commits.
Version control platforms
Version control platforms provide the version control functionality but add a lot more besides to improve the user experience for devotees of both the command line and GUI, to help different teams interact, and to provide integration with other DLM tools. For example, many version control platforms offer features such as:
- first-class command-line access for experts
- helpful GUI tools for less experienced users
- browser-based code review: diffs, commenting, tracking, tickets
- an HTTP API for custom integrations and chat-bots
- powerful search via the browser
- integration with issue trackers and other tools
We also need to consider how easy the system is to operate, particularly if we will run the system ourselves. An increasing number of organizations are choosing to use cloud-hosted or SaaS providers for their VCS, due to the reduction in operational overhead and the increased richness of integration offered by SaaS tools. There is also an argument that SaaS VCS tools are more secure than self-hosted tools, since most self-hosted VCS tools security management is average at best.
Some popular SaaS-based VCS platforms include Github, Bitbucket, CodebaseHQ and Visual Studio Online. These tools all offer Git as the version control technology plus at least one other (Subversion, Mercurial, and so on). Other options such as Beanstalk (http://beanstalkapp.com/) may work if you have a homogeneous code environment, because they are more focused on the Linux/Mac platforms.
Self-hosted VCS solutions are generally less-integrated with third-party tools, which may limit how easily they can be ‘wired together’. Examples of self-hosted VCS platforms include Gitolite, Gitlab, Bitbucket Server and Team Foundation Server.
Essential version control practices for DLM
Version control is central to the development, testing and release of databases, because it represents a “single source of truth” for each database. As discussed earlier, the VCS should contain everything that is needed in order to build a new database, at a given version, or update an existing database from one version to another. This may be necessary for a new deployment, for testing, or for troubleshooting ( e.g. reproducing a reported bug).
In addition, several other DLM practices depend on version control. Several activities carried out by governance rely on being able to inspect the state of the database at any released version. It is sometimes necessary to determine when a change was made, by whom and why. Also, when release-gates need sign-off, the participants can see what changes are in the release and what is affected by the change. Any audit is made much easier if the auditor can trace changes that are deployed in production all the way back to the original change in the VCS.
It’s essential that the process of building and updating databases from version control is as quick and simple as possible, in order to encourage the practices of continuous integration and frequent release cycles. This section will discuss some of the version control practices that will help.
Integrate version control with issue tracking
Version control pays dividends when it is integrated with issue tracking. This allows the developer to reference the source of defects, quickly and uniquely, and thereby save a lot of debugging time. It also allows the management of the development effort to check on progress in fixing issues and identifying where in the code issues are most frequent. Developers will also appreciate being able to automate the process of reporting how bugs were fixed and when. It also allows the team to share out the issue-fixing effort more equally and monitor progress.
Adopt a simple standard for laying out the files in version control
It is sometime useful to store database script files in version control in a format that matches or resembles a layout that will be familiar from use of GUI tool, such as SSMS or TOAD.
Generally, this simply means storing each object type in a subdirectory from a base ‘Database’ directory. For example, Database | Tables, Database | Stored Procedures, Database | Security, and so on. It is normal to store child objects that have no independent existence beyond the object they associated with the parent object. Constraints and indexes, for example, are best stored with the table creation scripts.
Making frequent, non-disruptive commits
In order to maintain a high level of service of a database, we need to integrate and test all changes regularly (see the Database Continuous Integration article).
To achieve this, we need to adopt practices that encourage regular commits of small units of work, in a way that is as non-disruptive as possible to the rest of the team. Any commit of a set of changes should be working and releasable. Feature toggles allow deactivating particular features but those features still need to work and pass tests before deployment. Consider a commit to be like the end of a paragraph of text: the paragraph does not simply trail off, but makes sense as a set of phrases, even if the text is not finished yet.
Adopt consistent whitespace and text layout standards
Agree and establish a workable standard for whitespace and text layout conventions across all teams that need to work with a given set of code or configuration files. Modern text editors make it simple to import whitespace settings such as the number of spaces to indent when the TAB key is pressed, or how code blocks are formatted.
This is especially important in mixed Windows/Mac/*NIX environments, where newline characters can sometimes cause problems with detecting differences. Agree on a convention and stick with it, but make it very simple for people to import the standardized settings; do not make them click through 27 different checkboxes based on information in a Wiki.
When detecting changes, a source control system will default to simply comparing text. It will therefore see any changes of text as a change. This will include dates in headers that merely record the time of scripting, and are irrelevant. It will also include text in comments, even whitespace, which in SQL has no meaning, in contrast to an indentation-based language such as Python. If your source control system just compares text, you need to be careful to exclude anything that can falsely indicate to a VCS that a change has been made.
Tools such as a database comparison tool will parse the text of the SQL to create a parse tree and compare these rather than the text. This not only prevents this sort of false positive but allows the user to specify exactly what a change is and what isn’t. If this sort of tool is used to update source control, then the only changes will be the ones that the user wants. However, this needs a certain amount of care since formatting of SQL Code can be lost unless it is flagged as a change.
Keep whitespace reformatting separate from meaningful changes
Even if you have a database comparison tool that will help avoid detecting ‘false changes’, it still helps to commit whitespace and comment reformatting separately from changes to the actual code i.e. that will affect the behavior of a script.
Figure 2 shows the colored console output for a comparing current to previous versions, after a commit that contained both whitespace reformatting, and a behaviour change, making the latter (an increase in the width of the LastName column from 50 characters to 90) much harder to spot.
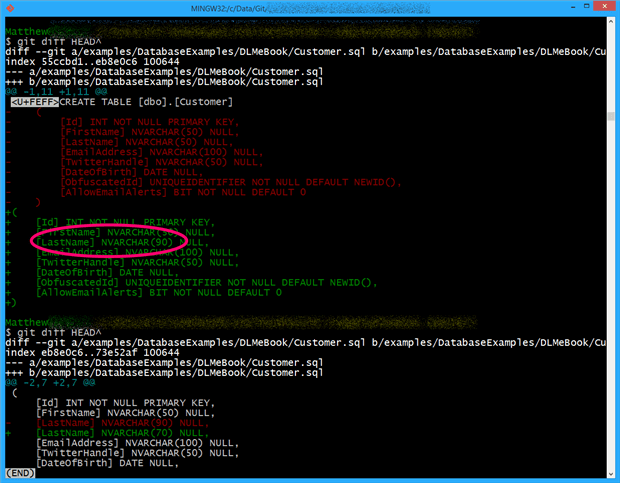
Figure 1: A commit that made whitespace and semantic changes.
If we separate out the whitespace and semantic changes, the colored console output highlights the meaningful change very clearly, in this example someone has reduced the column width from 90 to 70.
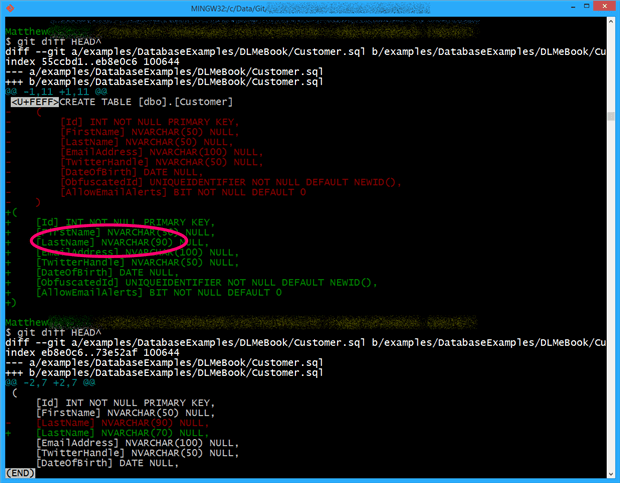
Figure 2: isolating a single semantic change
Just as with any changes to files in a VCS, separating reformatting changes from semantic changes is crucial for readability and tracing problems. With a DVCS like git, you can make multiple local commits (say two commits for whitespace and layout reformatting, followed by some semantic changes) before pushing to the central repository. This helps to encourage good practice in isolating different kinds of changes.
Plan how to coordinate application and database changes
A database can have a variety of relationships with applications, from almost total integration within the data layer of the application, to being a remote server providing data services via a protocol such as the Open Data Protocol ( OData). Commonly in enterprises, a single database will provide services to a number of applications, and provide integration, and reporting services, for them, via abstraction layers provided for each application, within the database. It means that there will be a number of perfectly valid approaches to managing the change process. At one extreme, the database sits in an entirely separate development regime, sometimes not even subject to the same version control, test and build processes as the application. At the other, the database code is treated on equal terms in source control to the rest of the code and settings of the application.
Where database and application are close-coupled, we can adopt a unified approach to the development and deployment of both application and database, and therefore a unified strategy for versioning a project, with all project resources organized side by side in the same repository. Of course, often this means little more than creating a directory for the database alongside the application, in the VCS, evolving the structure of the database rapidly alongside the application, with the necessary branching and merging (covered later), as their understanding of the problem domain evolves. For a relational database of any size, with complex object interdependencies, this can prove challenging, especially given that when the team need to upgrade an existing database with what’s in the VCS, then every database refactoring needs to be described in a way that will carefully preserve all business data.
For databases that support multiple applications, if the delivery of all the changes that span the applications and database haven’t been planned properly, then the subsequent ‘big bang’ integration between application and database changes can be painful and time-consuming. This, along with deploying the new versions of database and application to QA for testing, then on to the operations team for deployment to Staging and then, finally to Production, forms part of the infamous “last mile” that can delay releases interminably.
Databases, and their interactions with other databases, applications or services, are not immune from the general rules that apply to other interconnected systems. There are several database design and versioning strategies that can help to allow the component parts to change without causing grief to other components who are accessing it. By applying the rules that govern the interfaces between any systems, it is possible to make database changes without disrupting applications, as well as avoid complex branching strategies, and ensuring that our database code is free from dependencies on database configuration and server-level settings.
Every applications needs a published application-database interface
Regardless of the exact branching strategy, a team that creates an application that makes direct access to base tables in a database will have to put a lot of energy into keeping database and application in sync. When using “feature and release” branching, this issue will only worsen, the more branches we maintain and the more versions of the database we have in the VCS.
An application version should be coupled to an application-database interface version, rather than to a database version. Each application should have a stable, well-defined interface with the database, one for each application, usually, if more than one application uses a single database. A good interface implementation will never expose the inner workings of the database to the application, and will therefore provide the necessary level of abstraction.
Usually, the application development team owns the interface definition, which should be stored in the VCS. It forms a contract that determines, for example, what parameters need to be supplied, what data is expected back and in what form.
The database developers implement the interface, also stored in the VCS. Database developers and application developers must carefully track and negotiate any changes to the interface. If, for example, the database developer role wishes to refactor schema, he or she must do so without changing the public interface, at least until the application is ready to move to a new version, at which point the team can negotiate an interface update. Changes to the interface have to be subject to change-control procedures, as they will require a chain of tests.
The database developers will, of course, maintain their own source control for the database “internals,” and will be likely to maintain versions for all major releases. However, this will not need to be shared with the associated applications.
Keep database code in a separate repository from application code
Unless your database will only ever be used by one version of one application, which is unlikely with DLM, you should keep the database code in its own version control repository. This separation of application and database, and use of a published interface as described above, helps us to deploy and evolve the database independently of the application, providing a crucial degree of flexibility that helps to keep our release process nimble and responsive.
Adopt a “minimal” branching strategy
In many cases, we will store the files related to the main development effort in a common root subfolder of the VCS, often named trunk, but sometimes referred to by other names, such as main or mainline.
A VCS allows the team to copy a particular set of files, such as those in the trunk, and use and amend them for a different purpose, without affecting the original files. This is referred to as creating a branch or fork. Traditionally, branching has been seen as a mechanism to ‘maximize concurrency’ in the team’s development efforts, since it allows team members to work together and in isolation on specific features. A typical example is the creation of a “release” branch to freeze code for a release while allowing development to continue in the development branch. If changes are made to the release branch, normally as a result of bug fixes, then these can be merged into the development branch.
Branches can be a valuable asset to teams working with DLM, but should be used sparingly and with the idea that any given branch will only have a transient existence; just a few days. When working in a branch, there is a strong risk of isolating changes for too long, and then causing disruption when the merge ambush eventually arrives. It also discourages other good behavior. For example, if a developer is fixing a bug in a branch and spots an opportunity to do some general refactoring to improve the efficiency of the code, the thought of the additional merge pain may dissuade them from acting.
Instead we advocate that the team avoid using branches in version control wherever possible. This may sound like strange advice, given how much focus is placed on branching and merging in VCS, but by minimizing the number of branches, we can avoid many of the associated merge problems.
Each repository should, ideally, have just one main branch plus the occasional short-lived release branch. Instead of creating a physical branch for feature development, we use ‘logical’ branching and feature toggles. When combined with small, regular releases, many small repositories, and the use of package management for dependencies (covered later), the lack of branches helps to ensure that code is continuously integrated and tested.
The following sections outline this strategy in more detail.
Minimize “work in progress”
Teams often use branches in version control in order to make progress on different changes simultaneously. However, teams often end up losing much of the time they gained from parallel development streams in time-consuming merge operations, when the different work streams need to be brought together.
In my experience, teams work more effectively when they focus on completing a small number of changes, rather than tackling many things in parallel; develop one feature at a time, make it releasable. This reduces the volume of work-in-progress, minimizes context switching, avoids the need for branching, and helps keep changesets small and frequent.
Beware of organizational choices that force the use of branching
The need for branching in version control often arises from the choices, explicit or otherwise, made by people in the commercial, business, or program divisions of an organization. Specifically, the commercial team often tries to undertake many different activities simultaneously, sometimes with a kind of competition between different product or project managers. This upstream parallelization has the effect of encouraging downstream teams, and development teams in particular, to undertake several different streams of work at the same time; this usually leads to branching in version control.
Another organizational choice that tends to increase the use of branching is support for multiple simultaneous customized versions of a core software product, where each client or customer receives a special set of features, or a special version of the software. This deal-driven approach to software development typically requires the use of branching in version control, leading rapidly to unmaintainable code, failed deployments, and a drastic reduction in development speed.
While there are strategies we can adopt to minimize the potential for endless feature branches or “per-customer” branches, which we’ll cover shortly, it’s also better to instead address and fix the problems upstream with the choices made by the commercial or product teams.
Encourage the commercial teams to do regular joint-exercises of prioritizing all the features they want to see implemented, thus reducing the number of downstream simultaneous activities.
Avoid feature branches in favor of trunk-based development
A popular approach within development is to create feature branches in addition to release branches. We isolate a large-scale or complex change to a component or a fix to a difficult bug, in its own branch, so that it doesn’t disrupt the established build cycle. Other developers can then continue to work undisturbed on “mainline”. One of the major drawbacks of this approach is that it runs counter the principles of Continuous Integration, which require frequent, small changes that we integrate constantly with the work of others. By contrast, trunk-based development encourages good discipline and practices such as committing small, well-defined units of work to a single common trunk branch.
In SQL Server, use of schemas, and the permission system, is the obvious way of enabling trunk-based development. Schemas group together database objects that support each logical area of the application’s functionality. Ideally, the VCS structure for the database will reflect the schema structure, in the same way that C# code can be saved in namespaces.
Features within a given schema of a database will be visible only to those users who have the necessary permissions on that schema. This will make it easier to break down the development work per logical area of the database, and minimize interference when all developers are committing to trunk. It also means that the ‘hiding’ of features is extremely easy, merely by means of changing permissions.
Use feature toggles to help avoid branching
In application development, if we wish to introduce a new feature that will take longer to develop than our established deployment cycle, then rather than push it out to a branch we hide it behind a feature toggle within the application code. We maintain a configuration file that determines whether a feature is on or off. We then write conditional statements around the new feature that prevents it from running until enabled by the ‘switch’ in the configuration file. It means the team can deploy these unfinished features alongside the completed ones, and so avoid having to deployment till the new feature is complete.
In database development, it is relatively straightforward to adopt a similar strategy. As long as we have a published database interface, as described earlier, we can decouple database and application deployments, to some extent. The views, stored procedures and functions that typically comprise such an interface allow us to abstract the base tables. As long as the interface “contract” doesn’t change, then we can make substantial schema changes without affecting the application. Instead of isolating the development of a new version of a database feature in a branch, the new and the old version exist side by side in trunk, behind the abstraction layer.
It means that we can test and “dark launch” database changes, such as adding a new table or column, ahead of time, and then adapt the application to benefit from the change at a later point. The article Database Branching and Merging Strategies suggests one example of how this might be done using a “proxy stored procedure.
By a similar strategy, we can avoid creating custom branches per customer requirements. Instead, we can use ‘feature toggles’ or plugin modules to produce the effect of customization without the need for branching and per-client customization of the source code. Of course, systems with long lived customizations (for example a payroll system that must support different countries/regions regulatory frameworks) will probably also require architectural decisions promoting those requirements.
Make any non-trunk branches short-lived
Sometimes it is useful to create additional branches, particularly for fixing problems in the live environment, or for trying out new ideas. Branches that are short-lived can be a valuable asset to teams working with DLM. If a branch lasts only a few days, the person who created the branch knows exactly why it exists and knows what needs to be merged into the main branch; the drift from the main branch is small.
Branches that last for many days, weeks, or months represent a ‘merge nightmare’, where each branch is in effect a separate piece of software because the changes are not merged for a long time, possibly not until after the author of the changes has moved to a different team or even a different organization.
Account for differences in database configuration across envirohnments
As discussed earlier, database source code does not consist merely of a number of tables and programmable objects. A database system is dependent on a range of different database and server-level configuration settings and properties. Furthermore, a differences in some of these settings, between environments, such as differences in collation settings, can cause differences in behavior. As a result, we need to place into version control the scripts and files that define these properties for each environment.
However, we still want to use the same set of database scripts for a given database version to deploy that database version to any environment. In other words, databases schema code and stored procedures/functions should be identical across all environments (Dev, Test, Staging, and Production). We do not want to use different versions of database code for different environments, as this leads to untested changes and a lack of traceability. This means that we must not include in the scripts any configuration properties, such as data and log file locations, nor any permission assignments, because at that point, we need one set of database scripts per version per environment.
Use database configuration files and version them
A common source of problems with software deployments, in general, is that the configuration of the software is different between environments. Where software configuration is driven from text files, we can make significant gains in the success of deployment and the stability of the server environment by putting configuration files into version control. Where security is an issue then this should be within a configuration-management archive separate to the development archive. Whichever way it is done, it is best to think of it as being logically separate from database source because it deals with settings that are dependent on the server environment, such as mapping tables to drives, or mapping database roles to users and server logins.
Examples of configuration settings for databases include:
- Database properties such as file layouts – data file and log file
- SQL Server instance-level configuration – such as Fill factor, max server memory
- SQL Server database-level configuration – such as Auto Shrink, Auto Update Statistics, forced parameterization
- Server properties – such as collation setting
- Security accounts – users and logins
- Roles and permissions – database roles and their membership
Scripts or property files that define and control these configuration settings should be stored in version control in a separate configuration management source control archive. A general practice with SQL Server databases is to use SQLCMD, which allows us to use variables in our database scripts, for properties like database file locations, and then reads the correct value for a given environment from a separate file. SSDT also exports a SQLCMD file to allow the same script to be used in several environments.
This approach is particularly useful for DLM because it opens up a dialogue between software developers and IT Operations people, including DBAs; both groups need to collaborate on the location of the configuration files and the way in which the files are updated, and both groups have a strong interest in the environment configuration being correct: developers so that their code works first time, and operations because they will have fewer problems to diagnose.
We recommend one of two simple approaches to working with configuration files in version control, as part of Configuration Management. The first approach uses one repository with branch-level security (or multiple repositories if branch-level security is not available).
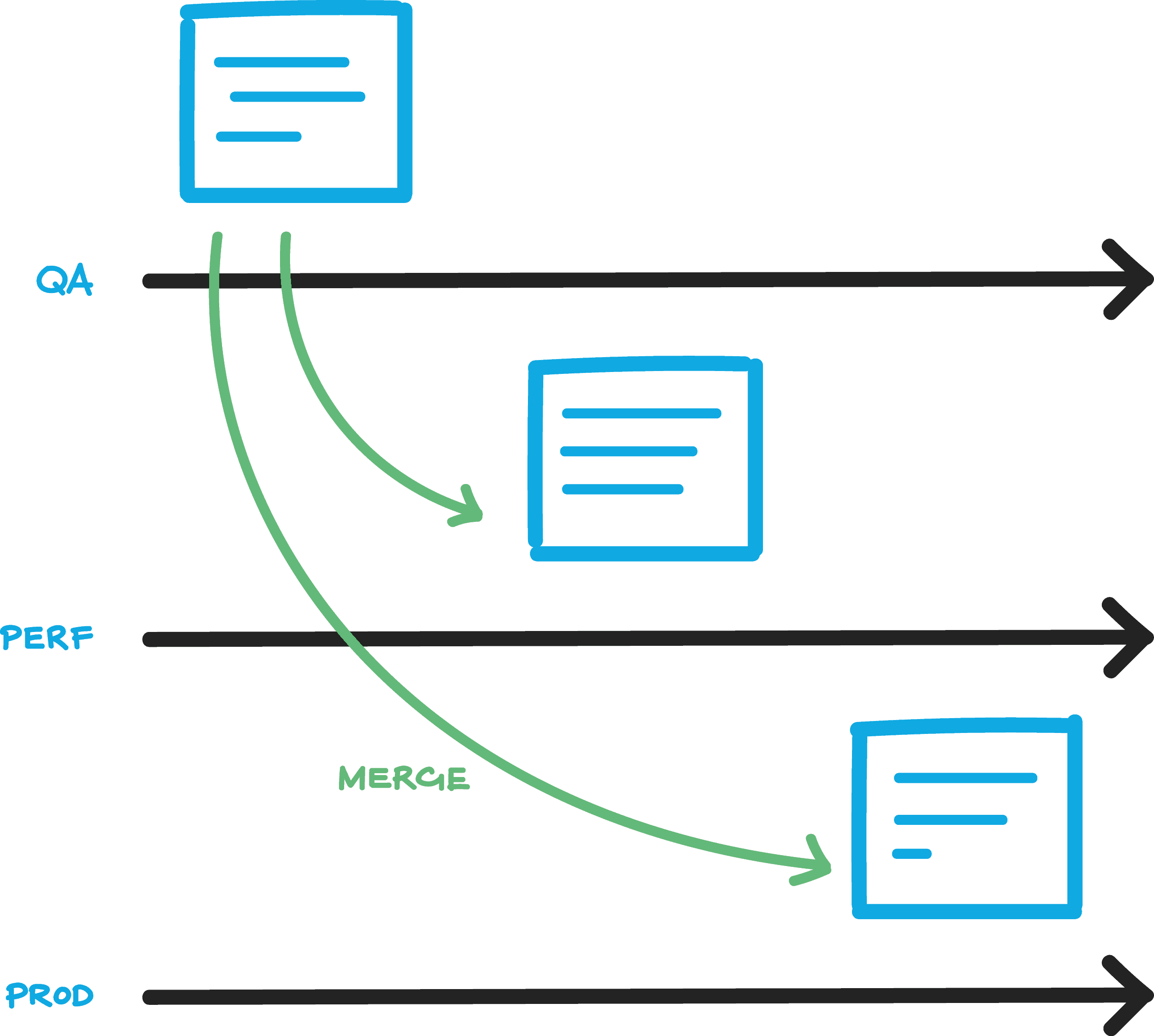
Figure 3: Configuration Management – single repository, branch-level security
In this model, each environment has its own branch in version control, and settings are merged from one branch to another. This makes security boundaries simple to enforce, but changes are more difficult to track compared to the second model.
The second approach uses a single branch with multiple side-by-side versions of a particular configuration file, one per environment. In this model, per-environment security is tricky to set up, but merging and tracking changes is easier than in the first approach.

Figure 4: Configuration Management – single repository, single branch
Either of these approaches will most likely lead to increased trust in environment configuration and more rapid diagnosis of environment-related problems.
Do not use per-environment repositories
The configuration information for all server environments should live in one version control CM archive. Do not use a repository per environment, because this prevents tracing of changes between environments. The only exception to this will be for compliance reasons where the regulatory framework requires that configuration settings for the Production environment are kept in a separate repository to all other configuration values.
Use packaging to deal with external dependencies
Many database applications have dependencies on third party modules. Rather than import into our VCS every module required by any of our applications, we can integrate these libraries and dependencies through packaging, for example using NuGet packages for .NET libraries, or Chocolatey for Windows runtime packages. We can specify which versions of which libraries each application repository depends on, and store that configuration in version control. At build time the packages containing the library versions we need are fetched, thus decoupling our dependencies on external (to our repo) libraries from the repositories organization.
We can also use package management to bring together configuration and application or database packages by having the configuration package depend on the generic application or database package, which in turn might depend on other packages.
Summary
By putting database code into source control, we provide a way of making it easier to coordinate the work of the different teams who share responsibility for the database. At different points in the life of a database, it is the focus of very different types of activities, ranging from creating an initial data model to decommissioning.
Version control acts as a communication channel between teams, because the changes captured in the version control system are treated as the single definitive ‘source of truth’ for people to collaborate on, bringing together delivery, governance and operations around a common DLM approach.
A working database will have a variety of materials that are required by the delivery team, governance or operations. With source-controlled archives, it is always obvious where the source of any material is, who made which alteration and update, when and why; Any materials, whether code, instructions, training materials, support information, configuration items, step-by-step disaster recover procedures, signoffs, release documents, entity-relationship diagrams or whatever, can be accessed easily.
Version-control isn’t the core of DLM but it makes it achievable by providing a source of information that is accessible, traceable, reliable, repeatable, and auditable.

DevOps, Continuous Delivery & Database Lifecycle Management
Go to the Simple Talk library to find more articles, or visit www.red-gate.com/solutions for more information on the benefits of extending DevOps practices to SQL Server databases.
Load comments